| |
 |
|

|


|
|
| |
SAS (Statistical Analysis System) is a statistical software as well as
a programming language that can easily manipulate both small and large
sets of data. Commands are available that allow you to use or
view all or part of your data set in a variety of ways. Data
can be reshaped, merged, redefined, updated, edited, and analyzed
using a variety of procedures (i.e., PROC statement). Elaborate reports
and forms can be generated and data may be graphed. These
characteristics make SAS one of the most popular statistical
software packages available.
The purpose of this page is to provide a brief introduction on;
- general SAS source code structure
- explain how to use SAS on an ODU Unix server for CEE 700/800 course
|
| |
In order to learn about using the SAS, you need to first understand
a few of its basic definition and terminology. The tables shown
below provide a brief description of some terms that will be used throughout
this quick quide.
 Data Terminology
Data Terminology
|
-
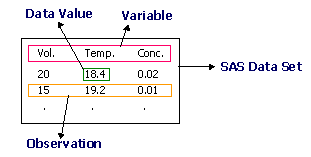
An easy way to visualize data is as a chart or table
of information with the data organized by columns and rows.
The whole chart is called a data set. Each column heading is
a variable, while
each row of data is an observation.
Looking at the figure below, each
observation is composed
of entries in the following fields:
Volume, Temperature, and Concentration.
| Variable |
Pieces of categorical information like Volume, Temperature, and
Concentration. Equivalent to an 'Attribute' in DBMS |
| Data Value |
A single value, such as a temperature reading |
| Observation |
A set of data values. For example, it could be
a volume, a temperature and a concentration of a
single sample. Equivalent to a 'Record' in DBMS |
| SAS Data Set |
A collection of all the data (=Observations) and category
information (=Data) with which you are
currently working. Equivalent to a 'Table' in DBMS |
| Missing Value |
When data value is not available for a particular
observation, OR illegal/mistyped characters have been
entered, the value is simply considered missing and will not
be used in calculations performed by PROC statements. (i.e.,
at least you'll not get an error message) |
|
|
Programming Terminology
|
-
| Data Block |
Portion of SAS source code used to read/assign/create
and manipulate a data set |
| Procedure Block |
Portion of SAS source code for specifying desired statistical
procedures/algorithms. [called 'PROC' statement block] Many procedures
are available in SAS. |
|
|
SAS File Terminology
|
| Program File |
Set of instructions to SAS. (=SAS source code) It has a file
extention of '.sas' For example, 'abc.sas' or 'median.sas', etc. |
| Listing File |
Output file for your SAS source code (if your SAS source code has no error).
This could be a listing of a data set, the calculated means of
your variables, or a myriad of other possibilities. If you have
error(s) in your SAS source code, no output file will be generated.
It has a file extention of '.lst' For example,
'abc.lst' or 'median.lst', etc.
|
| Log File |
Log outcome of each statement in your SAS source code as the SAS executes
them. If there is error(s), it will log error messages. Thus,
always take a look at log file first after
each SAS source code execution to determine
whether the execution was successful. If there was error(s), use error
messages in the log file to locate & correct problematic statements in
your SAS source code. It has a file extention of '.log' For example,
'abc.log' or 'median.log', etc.
|
|
-
Each time you're running a SAS source code (=program file), you'll generate
output file(s). if your SAS source code has no errors and all SAS
procedures in your SAS source code were executed correctly, then
you'll get two output files (=listing file + log file).
However, if your SAS source code has an error(s), you'll get only one output file
(=log file).
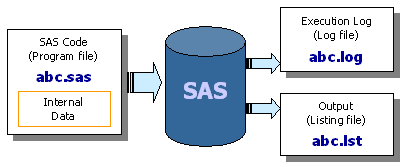 SAS Run Scenario (A) - Combined SAS source code and Data
(via CARDS statement)
SAS Run Scenario (A) - Combined SAS source code and Data
(via CARDS statement)
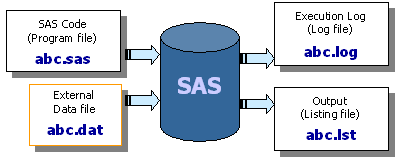 SAS Run Scenario (B) - Separate SAS source code and Data
(via INFILE statement)
SAS Run Scenario (B) - Separate SAS source code and Data
(via INFILE statement)
|
|
Core SAS Source Code Elements
|
| |
| OPTIONS [options]; |
|
Formatting options |
| TITLE#; |
|
Optional Descriptive titles (upto 10 titles, align centered; substitute # with incremental numbers) |
| FOOTNOTE#; |
|
Optional Descriptive footnotes (upto 10 titles, align centered; substitute # with incremental numbers) |
| DATA [data set name]; |
|
Define/assign Data set |
| INPUT [variable name and format]; |
|
Data input statements with variable names and formats |
| CARDS; |
|
|
| ??? |
|
Actual data |
| ??? |
|
|
| ; |
|
|
| PROC [procedure]; |
|
SAS Procedure statement, mainly a keyword and options (with Data set) |
| PROC [procedure]; |
|
Output statement (PRINT, PLOT, etc.) |
(A) - Combined SAS source code and Data
(via CARDS statement)
| OPTIONS [options]; |
|
Formatting options |
| TITLE#; |
|
Optional Descriptive titles (upto 10 titles, align centered; substitute # with incremental numbers) |
| FOOTNOTE#; |
|
Optional Descriptive footnotes (upto 10 titles, align centered; substitute # with incremental numbers) |
| DATA [data set name]; |
|
Define/assign Data set |
| INFILE 'filename'; |
|
External datafile |
| INPUT [variable name and format]; |
|
Data input statements with variable names and formats |
| PROC [procedure]; |
|
SAS Procedure statement, mainly a keyword and options (with Data set) |
| PROC [procedure]; |
|
Output statement (PRINT, PLOT, etc.) |
(B) - Separate SAS source code and Data
(via INFILE statement)
Shown above are two typical skeleton SAS source code structures.
A SAS source code has four main components of;
- Options and Titles/Footnotes
- Data Input
- Procedure (=analyses)
- Output (=plot & print of results)
A normal SAS source code requires/allows;
- SAS source should be in a plain vanilla ASCII (i.e., text-only) format.
- Any blank line(s) between statements will be ignored.
- Each SAS statement MUST end with ;
- Each SAS statement can start from any column, and there is no max. column restriction.
- SAS treats both UPPER character and lower character the same.
- Comments can be inserted by surrounding them with /* and */.
|
Options
|
-
OPTIONS statement set SAS system options. Syntax is
OPTIONS [options];
where options may include
| CENTER |
center-align SAS outputs |
| NODATE |
do not print date of analysis |
| LINESIZE=# |
set the max. column for the output. # of 132 is default.
For printing in 8.5"x11" paper, use 80 or less |
| SOURCE |
include SAS source code in log file |
|
Title and Footnote
|
-
TITLE# and FOOTNOTE# statement allow user-defined title(s) and footnote(s)
for describing SAS output. Max. upto 10 titles and footnotes.
Both title and footnote are center aligned; substitute # with incremental numbers.
Even though title and footnote are not required to run source codes, it
is always a good idea to put them in your source code for
your own sanity(!) -- make it sure you
modify/update them each time you revise your source code.
|
TITLE1 'this is title 1';
TITLE2 'this is title 2';
FOOTNOTE1 'this is footnote 1';
FOOTNOTE2 'this is footnote 2';
|
|
Data
|
-
Each SAS procedure requires you to indicate the data set to
be used for the analysis. Data may be either text or numerical. Text are
characters, numbers, and symbols. Numerical data are numbers that will
be used mathematically.
A data set is named by the user with the DATA statement. Data is then
entered as a part of the program using the CARDS statement (i.e., combined SAS source code
and data) or from an external file using the INFILE statement (i.e., separate SAS source code
and data).
SAS Run Scenario (A) - Combined SAS source code and Data
(via CARDS statement)
SAS Run Scenario (B) - Separate SAS source code and Data
(via INFILE statement)
Both approaches have pros and cons; CARDS (i.e., combined) approach is
ideal if the size of data is relatively small and/or you want to keep
data set together with a corresponding SAS source code for a archival
purpose. INFILE approach is definitely recommended if the size of your
data set is large (n > 200) and you have to use the same data set
repeatedly.
SAS reads each line of your input and writes it to a SAS data set as an
observation. Entering RUN; at the end of your DATA step establishes a
block terminator after that section and is good programming technique.
(A) - Combined SAS source code and Data
| DATA [data set name]; |
data set name could be anything you can imagine
as long as it is less than or equal to 8 chars |
| INPUT [variables] [@@]; |
variable names (of your choice).
- Variable names must be one to eight characters (letters, numbers, or underscore)
beginning with a letter or underscore.
- If the name represents text, the name must be followed by a space and a dollar sign ($).
For example, a variable 'name' will represent the last names, you
need to define 'name' variable as
name $
- A text data value can be up to 250 characters (letters, numbers, spaces, punctuation)
if data values are pre-formatted
- @@ can be used to force reading loop of observations
|
| CARDS; |
start of actual input data values |
| ... |
actual input data values |
| ... |
|
| ; |
tell SAS that data input was completed. Equivalent to RUN; |
Example 1) - List input format
|
DATA class;
INPUT name $ initial $ sex $ year grade1 grade2 grade3;
CARDS;
Jones A m 3 88 79 88
Smith K f 2 92 85 92
Jackson B m 3 95 . 82
Abrams D m 4 78 85 88
;
|
Notice the format of the INPUT statement. This CARDS method is
using List input format (i.e., read data values as is given). SAS scans the first card for the first
nonblank column, reads the value through the next blank, and assigns it
to the first variable name. The next nonblank column is the beginning
of the next value and so on until the card is finished.
- Each variable name is separated by a blank from the name preceding it.
- Every field in the data must be named in the input statement
because there is a one to one match as it reads the data.
- If numerical data is missing for a single variable,
a period (.) must be included as a place holder.
- Character field values have a limit of eight characters in List
input format (i.e., read data values as is given) and may not contain blanks.
Example 2) - Column input format
|
DATA class;
INPUT name $ 1-10 initial $ 12 sex $ 14
year 16 grade1 18-19 grade2 21-22 grade3 24-25;
CARDS;
Jones A m 3 88 79 88
Smith K f 2 92 85 92
Jackson B m 3 95 . 82
Abrams D m 4 78 85 88
;
|
Notice the format of the INPUT statement. This CARDS method is using
Column input format (i.e., data values are pre-formatted). The beginning
column for each variable is listed, followed by a dash (-) and then the
ending column.
- A column range is defined by the lower column number followed by the higher.
- If a field is blank, SAS reads it as missing data.
- A period (.) may be entered to indicate that a field is blank.
- Individual character values can be up to 250 characters long and can contain blanks.
Example 3) - A Data input statement for a univariate data set, y and x)
|
DATA oink;
/* Assign name "oink" for your data set. You can assign */
/* any name of your choice as long as it is 8 letters max.*/
INPUT Y X @@;
/* Y, X = data will be in Y first and X second sequence */
/* @@ = Loop indicator. After reading first 2 values for */
/* Y and X, third value will be treated as Y, and */
/* fourth value as X, and repeat the loop until data */
/* set exhausts */
CARDS;
/* Indicating that the next line of this CARDS line is */
/* the beginning of data set */
90.01 0.99 89.05 1.02 91.43 1.15
93.74 1.29 96.73 1.46 94.45 1.36
.....
.....
/* Actual data set for Y and X. As long as there is a */
/* space between values, SAS will treat them as separate */
/* value. No special formating is necessary other than */
/* aesthetic purposes */
;
/* Tell SAS that this is the end of data set to be read */
/* for analysis */
|
You can also input by 'variable dependency' method, which would
effectively eliminate the typical replication of 'balanced' input format.
Next example would be self-explanatory.
Example 4) - A 'variable dependency' method
input statement for a univariate data set, y and x relicates.
DATA sparky;
/* Assign name "sparky" for your data set. You can assign */
/* any name of your choice as long as it is 8 letters max.*/
INPUT Y n;
do i=1 to n;
input X @@;
output;
end;
datalines;
10 13
228 229 218 216 224 208 235 229 233 219 224 220 232
20 11
186 229 220 208 228 198 222 273 216 198 213
30 12
179 193 183 180 143 204 114 188 178 134 208 196
40 14
130 87 135 116 118 165 151 59 126 64 78 94 150 160
50 11
154 130 130 118 118 104 112 134 98 100 104
;
which is equivalent to
DATA sparky;
INPUT Y X @@;
CARDS;
10 228 10 229 10 218 10 216 10 224
10 208 10 235 10 229 10 233 10 219
10 224 10 220 10 232
20 186 20 229 20 220 20 208 20 228
20 198 20 222 20 273 20 216 20 198
20 213
30 179 30 193 30 183 30 180 30 143
30 204 30 114 30 188 30 178 30 134
30 208 30 196
40 130 40 87 40 135 40 116 40 118
40 165 40 151 40 59 40 126 40 64
40 78 40 94 40 150 40 160
50 154 50 130 50 130 50 118 50 118
50 104 50 112 50 134 50 98 50 100
50 104
;
|
(B) - Separate SAS source code and Data
| DATA [data set name]; |
data set name could be anything you can imagine
as long as it is less than or equal to 8 chars |
| INFILE 'filename'; |
define an external data filename to be read
during SAS source code execution |
| INPUT [variables] [@@]; |
variable names (of your choice).
- Variable names must be one to eight characters (letters, numbers, or underscore)
beginning with a letter or underscore.
- If the name represents text, the name must be followed by a space and a dollar sign ($).
For example, a variable 'name' will represent the last names, you
need to define 'name' variable as
name $
- A text data value can be up to 250 characters (letters, numbers, spaces, punctuation)
if data values are pre-formatted
- @@ can be used to force reading loop of observations
|
Example) - List input format
|
DATA class;
INFILE 'class_grade.dat';
INPUT name $ initial $ sex $ year grade1 grade2 grade3;
RUN;
The file, class_grade.dat contains following data
Jones A m 3 88 79 88
Smith K f 2 92 85 92
Jackson B m 3 95 . 82
Abrams D m 4 78 85 88
|
|
Procedure Statement (PROC)
|
-
SAS has many PROCEDURES for data display and statistical analysis. They are
usually referred to as PROC and then the name of the requested
activity and a semicolon (;).
Each PROC is actually a separate program
and each PROC requires a SAS data set to work. You need to specify which
SAS data set to use and if there are any options or restrictions on
the data set.
The lines following the PROC may hold more instructions.
Statements all end with a semicolon (;). More than one
statement may be on the same line, but the statements must
be separated by at least one semicolon (;).
The basic form of a procedure is
-
PROC xxx
DATA=name
<OPTIONS>;
control statements;
RUN;
Example) -
A Procedure statement for estimating a simple linear
regression model of Y = ax+b
|
PROC REG
DATA=sample1;
MODEL Y = X /P R;
/* P = Calculates predicted values from the input */
/* data as well as a estimated regression model */
/* R = Calculates an analysis of the residuals */
OUTPUT OUT=A P=YHAT R=RESID STUDENT=STDR;
/* A = Actual observation values */
/* P = Predicted values based on the regression model */
/* R = residuals between A and P */
|
|
Working with Variables
|
-
Once initial variables are defined in INPUT statement,
a new variable may be created or an old variable modified by
using a mathematical expression.
new_var = expression;
The mathematical operations will be done in a
hierarchial order, not from left to right. Mathematical expressions
within parentheses are performed first. The actual order of
operation within parentheses or in the absence of parentheses
is exponentiation, multiplication and division, and lastly
addition and subtraction. Use parentheses to ensure that
the expressions are evaluated according to your specifications.
- New Variable
-
var12 = var11 + 5;
var12 = var10 - var11;
var12 = var12 * var9;
var12 = (var8 + var9 + var10 + var11) / 4;
- Modify an old variable
-
var3 = var3*1.05;
- Create on the fly
-
DATA orange;
INPUT var1 var2;
var3 = var1 + (var2 * 4);
CARDS;
- Use with IF statement
-
IF var3 = 5 THEN var10 = 6;
ELSE var10 = 1;
- Logical Operators
-
| Equals
|
=, EQ
|
if X1 = 8;
if X6 EQ "N/A";
|
| Not equal
|
<>, NE
|
if X2 NE 3;
if site <> "chesapeake";
|
| Greater than
|
>, GT
|
if X5*0.125 > 0.4;
if X5*0.125 GT 0.4;
|
| Less than
|
<, LT
|
if X7/2.3 < 1;
if X7/2.3 LT 1;
|
| Greater than or equal
|
>=, GE
|
if X11 >= 11;
if X11 GE 11;
|
| Less than or equal
|
<=, LE
|
if X33 <= 200;
if X33 LE 200;
|
| logical AND
|
AND
|
if (SRPspring = SRPfall) AND (log(SRPspring) > 0.6);
|
| logical OR
|
OR
|
if (SRPspring = SRPfall) OR (log(SRPspring) > 0.6);
|
| logical NOT
|
NOT
|
if (TNsummer GT 25) NOT (log(TNsummer) > 3.81);
|
|
- Transformation
-
Variable that you create/define
(which can be any name) for 'X' = SAS Function Format;
- Example)
- FatHorse=log10(X);
- AreYouSerious=log10(X);
| to Natural logarithm (base e, loge)
|
lnX = log(X);
|
| to Common logarithm (base 10, log10)
|
logX = log10(X);
|
| to Exponential function
|
expX = exp(X);
|
| to 'f' power function
|
pwX = X**f;
(i.e., X**2.7 is equivalent to X2.7)
|
| to square root
|
sqRootX = sqrt(X);
|
| to uniform(0,1) random number
|
ranX = ranuni(X);
|
| to sine function
|
sinX = sin(X);
|
| to cosine function
|
cosX = cos(X);
|
| to tangent function
|
tanX = tan(X);
|
|
- Making a new (filtered) dataset from existing dataset
-
DATA new_dataset;
SET existing_dataset;
[filtering statements]
OUT=new_dataset;
Examples)
DATA y20082009;
set Coliform; /* coliform data series 1990-2010 */
if Year = "2008" or Year = "2009";
OUT=y20082009; /* coliform dataset containing only 2008 and 2009 data */
DATA ERDOcategory;
SET ERDO; /* Dissolved Oxygen conc. from Elizabeth River */
if DO <= 4.00 then DOClass = 3;
else if (DO <= 6.00) and (DO > 4.00) then DOClass = 2;
else DOClass = 1;
OUT=ERDOcategory; /* DO pre-categorized into classes */
- Concatenating string variables
-
name = firstname || lastname;
Example)
DATA n_split;
INPUT firstname $ lastname $ @@;
CARDS;
Elvis Presley John Adams David Bowie
;
DATA n_merge;
set n_split;
name= firstname || lastname;
OUT=n_merge;
PROC PRINT DATA=n_split;
PROC PRINT DATA=n_merge;
---------------------------
Obs firstname lastname
1 Elvis Presley
2 John Adams
3 David Bowie
Obs firstname lastname name
1 Elvis Presley Elvis Presley
2 John Adams John Adams
3 David Bowie David Bowie
|
|
Logistics - Writing and Running SAS Source Codes
|
| |
Always examine log file first after
each SAS source code execution to determine
whether the execution was successful. If there was error(s), use error
messages in the log file to locate & correct problematic statements in
your SAS source code. Log file has a file extention of '.log' For example,
'abc.log' or 'median.log', etc.
SAS reacts to your source code errors during execution
by putting followings in the log file;
- usually underlines the error
- identifies the error by number
- enters syntax check mode
Hence, most common SAS syntax error that you'd encounter is
incorrect use of 'Tab' key
for 'Space' key -- DO NOT USE 'Tab' key
in your SAS source.
Followings are common error messages from log file that you can interpret
and track down possible SAS source code errors.
-
|
Syntax Errors
|
-
155: THE VARIABLE NAME IS NOT ON THE DATA SET
- Variable name is misspelled.
- A procedure is referenced without the DATA=option and the most recently
created data set was used.
180: STATEMENT IS NOT VALID OR IT IS USED OUT OF PROPER ORDER.
- Semicolon omitted.
- SAS keyword is misspelled.
- Specified a DATA step statement outside the DATA step or a PROC step
statement outside of a PROC step.
- Entered invalid characters in columns 73-80 of the statement in
error.
183: THE PROCEDURE NAME IS NOT KNOWN TO THE SYSTEM.
- Check the spelling of the name.
620: OBSOLETE FORM OF STATEMENT OR TEXT82 OPTION INCORRECT.
- Put text strings for Titles and Footnotes in quotes.
107: CHARACTER LITERAL HAS MORE THAN 200 CHARACTERS
- Used a single quote mark within a quoted string. For example,
TITLE1 'Norfolk's Seasonal BOD measurements for 2011';
should be
TITLE1 "Norfolk's Seasonal BOD measurements for 2011";
|
Problems with Data
|
-
NOTE: SAS WENT TO A NEW LINE WHEN INPUT STATEMENT REACHED PAST THE END OF A LINE.
NOTE: INVALID DATA FOR A IN LINE nn
- SAS encountered character data where numeric was expected. It lists out
the line of data for your inspection with a ruler.
|
Execution/Logic Problems
|
-
- Sample size is too small for some PROC, i.e.,
you ran with a small sample something like OBS=3
- Use PROC PRINT on a huge sample.
- Some Regression procedures are very data dependent.
|
|
|